


Artificial intelligence (AI) in microbial diagnostics represents an established and rapidly evolving approach of analysing the presence of disease within the patient population while providing precise and quick results. Globally, bespoke AI models are developed to analyse microbial samples, make predictions, and establish a link between the pathogen and symptoms. Currently, AI is being used in several areas of microbiology, including virology, parasitology, mycology, and bacteriology, particularly in diagnostics. AI-powered technologies, including machine learning (ML) and deep learning (DL), analyze complex microbial data such as genomic sequences, phenotypes, and clinical metadata, enabling early detection of infectious diseases and personalized treatment strategies. Even with these advancements, there are still significant challenges affecting AI diagnostics at present. Ethical concerns jeopardise patient confidentiality and equitable access to healthcare. AI models’ reliance on high-quality datasets for training leads to technical restrictions and may result in errors when applied to diverse microbial strains or under-represented populations. Additionally, AI systems usually require complex infrastructure and processing capacity, which restricts their application in low-resource contexts. Operational challenges such as too much reliance on automated systems, could compromise human judgement in critical decision-making situations. Despite being slower, traditional techniques offer subtle insights that AI might miss. Furthermore, the ethical and technical challenges of integrating AI in microbiological diagnostics are not adequately addressed by regulatory frameworks and standardisation. In order to maximise the use of AI in microbiological diagnosis, this study emphasises the necessity of addressing those drawbacks. By combining AI with conventional methods responsibly, healthcare can enhance diagnostic precision while reducing the hazards associated with developing technologies.
Artificial Intelligence (AI), Microbial Diagnostics, Machine Learning (ML), Deep Learning (DL), Ethical Challenges
WHAT IS AI?
Artificial Intelligence (AI) is a subdiscipline of computer science, a branch that aims at approaching tasks with extended and simulated human intelligence through computational tools and systems.1 Artificial intelligence encompasses computational systems designed to perform tasks that typically require human intelligence, though the underlying mechanisms may differ substantially from human cognitive processes. These systems use algorithms and statistical models to recognize patterns, make predictions, and solve problems like a human does.1 The manner in which humans approach a task differs significantly from the way an AI would. The evaluation rubric taken by an AI model is designed to solve specific problems through pattern recognition and data-driven learning, with the primary goal of augmenting human capabilities. AI systems differ from traditional computing programs through their ability to learn from data and improve performance without explicit reprogramming the posterior assumptions. Unlike rule-based programs that execute predetermined instructions, AI systems can identify patterns, adapt to new inputs, and make decisions based on probabilistic models trained on large datasets.1 AI systems employ diverse learning mechanisms. In supervised learning, algorithms are trained on labeled datasets to recognize patterns and make predictions. Deep learning architectures, such as convolutional neural networks (CNNs), process data through multiple layers of interconnected nodes, with each layer extracting increasingly abstract features. Other approaches, including decision trees, support vector machines, and ensemble methods, use different mathematical frameworks to achieve similar pattern recognition goals. With given data and time to refine the algorithm, an AI is proven to perform complex tasks such as image recognition, language processing and problem-solving.2 Building on these capabilities, exponential AI adoption is observed along various fields, offering unprecedented efficiency and accuracy. In healthcare sector especially, AI-driven technologies are enhancing disease diagnosis, treatment planning, and even robotic surgeries. One particularly promising area is microbial diagnosis, where AI is accelerating the identification of pathogens, improving accuracy, and aiding in the development of targeted treatments. By leveraging vast datasets and sophisticated algorithms, AI is not only complementing human expertise but also pushing the boundaries of what is possible across diverse domains.
Brief history of AI in microbial diagnostics
The history of AI in microbial diagnostics shows a significant evolution from traditional methods to more advanced systems that enable efficient and more accurate diagnoses. In the early phase of its conception, microbial diagnostics solely relied on conventional approaches such as culture techniques, microscopy, and molecular analysis. AI revolutionizing the field is only observed in the recent years, particularly with the advancement of machine learning (ML) and deep learning (DL). These AI-driven techniques can rapidly analyse complex datasets, such as genetic sequences and clinical data, to identify microorganisms with exceptional precision.3 AI has also aided in predicting antimicrobial resistance (AMR) and understanding microbial interactions, making it an invaluable tool in personalized medicine and public health surveillance.4,5
The application of Artificial Intelligence (AI) in microbial diagnostics has transformed significantly, driven by advancements in computational efficiency, machine learning, and biological data analysis. In its formative years (1950s-1980s), AI was not more than a basic logic-solving machine that was focused on solving basic mathematical and logic problems, far removed from medical or microbiological applications. Microbial diagnostics during this period mainly involved culture-based methods (growing bacteria on selective media) and microscopy, methods that required skilled manual interpretation. Later in the 1980s and 1990s, systems such as MYCIN revolutionized the scope of diagnosis of various bacterial as well as blood-borne diseases such as sepsis and meningitis among many other diseases.6,7 MYCIN was a rule-based expert system that employed backward chaining inference to diagnose diseases and recommend antibiotics based on the inputs provided by the user.6,7 However, MYCIN faced significant barriers to clinical adoption, including the computational limitations of the era, concerns about liability, and the challenge of maintaining and updating its knowledge base as medical understanding evolved. These limitations highlighted the need for more adaptive, data-driven approaches. In the 2000s, the field of microbial diagnostics began leveraging machine learning (ML) and pattern recognition algorithms for more sophisticated and accurate pathogen identification. Automated Susceptibility Testing systems like VITEK 2 and Phoenix use machine learning algorithms to determine the susceptibility of microorganisms to antibiotics.8 AI algorithms were employed to analyse flow cytometry data to detect, classify, and quantify microorganisms in real time.9 These algorithms could differentiate between bacteria, fungi, and other microbial contaminants in clinical samples based on cell size, shape, and fluorescence signals.9 BacT/ALERT, a microbial detection system developed by, used machine learning algorithms to detect the growth of bacteria and fungi in blood culture bottles.10 Even traditional techniques such as PCR (polymerase chain reaction) became more efficient with AI, enhancing and automating the detection and quantification of given DNA/RNA samples.11 Machine learning data was integrated with an AI algorithm to be used in conjunction with microarrays, which enhanced its detection capabilities by scanning thousands of genetic markers simultaneously or gene expression patterns. This allowed microarrays to be used in identifying pathogens and detecting resistance genes in microbes.12 One of the notable breakthroughs of this era was MALDI-TOF MS (Matrix-assisted laser desorption ionization-time of flight mass spectrometry). MALDI-TOF uses protein profiles to identify bacteria and fungi based on their mass spectra.13 AI-powered algorithms analyse these spectra to match them against reference databases of microbial species, significantly reducing the time for diagnosis compared to traditional culture-based methods.13 A procedure that used to require several days such as culturing bacteria and subsequent biochemical testing, can now be completed within minutes. MALDI-TOF MS remains a cornerstone technology in clinical microbiology laboratories and has expanded beyond routine identification to include antimicrobial resistance profiling, strain typing, biomarker discovery, and integration with machine learning algorithms for enhanced diagnostic accuracy for identifying pathogens like E. coli, Staphylococcus aureus, and Candida species.7,14 In the 2010s, the advent of Next-generation sequencing (NGS) allowed large scale analysis, integration and interpretation of microbial data more accessible. (NGS) is a powerful technology that has revolutionized genomics and has profound applications in microbial diagnostics, enabling rapid, comprehensive, and highly sensitive analysis of microbial DNA and RNA.15 Unlike traditional sequencing techniques, such as Sanger sequencing, NGS allows for the parallel sequencing of millions of DNA fragments, providing a much more detailed view of microbial genomes, communities, and resistance patterns of said microbial species. Platforms such as Explify MetaPhlAn (Metagenomic Phylogenetic Analysis) utilise AI and NGS technology to sequence microbial genomes.15,16 In recent times, an extensive integration into deep learning AI have further improved the scope of microbial diagnostics. CRISPR technology being a notable example, has also been adapted for rapid and sensitive detection of microbial pathogens. Techniques like SHERLOCK17 and DETECTR18 utilize CRISPR to identify specific nucleic acid sequences associated with pathogens, enabling quick diagnosis. Overview of the progression of artificial intelligence in diagnostic applications is depicted in Figure 1. AI has played a crucial role in increasing the efficiency of existing technologies and also helped in building derivative methods such as Whole gene sequencing (WGS), anti-microbial resistance (AMR) prediction and metagenomic sequencing among other technologies used in the sector.15 Advancements in AI have greatly enhanced the speed and accuracy of microbial diagnostics, while also enabling the efficient analysis of large and complex datasets. As a result, AI has become an indispensable tool in modern clinical microbiology, supporting more timely and informed decision-making in healthcare.
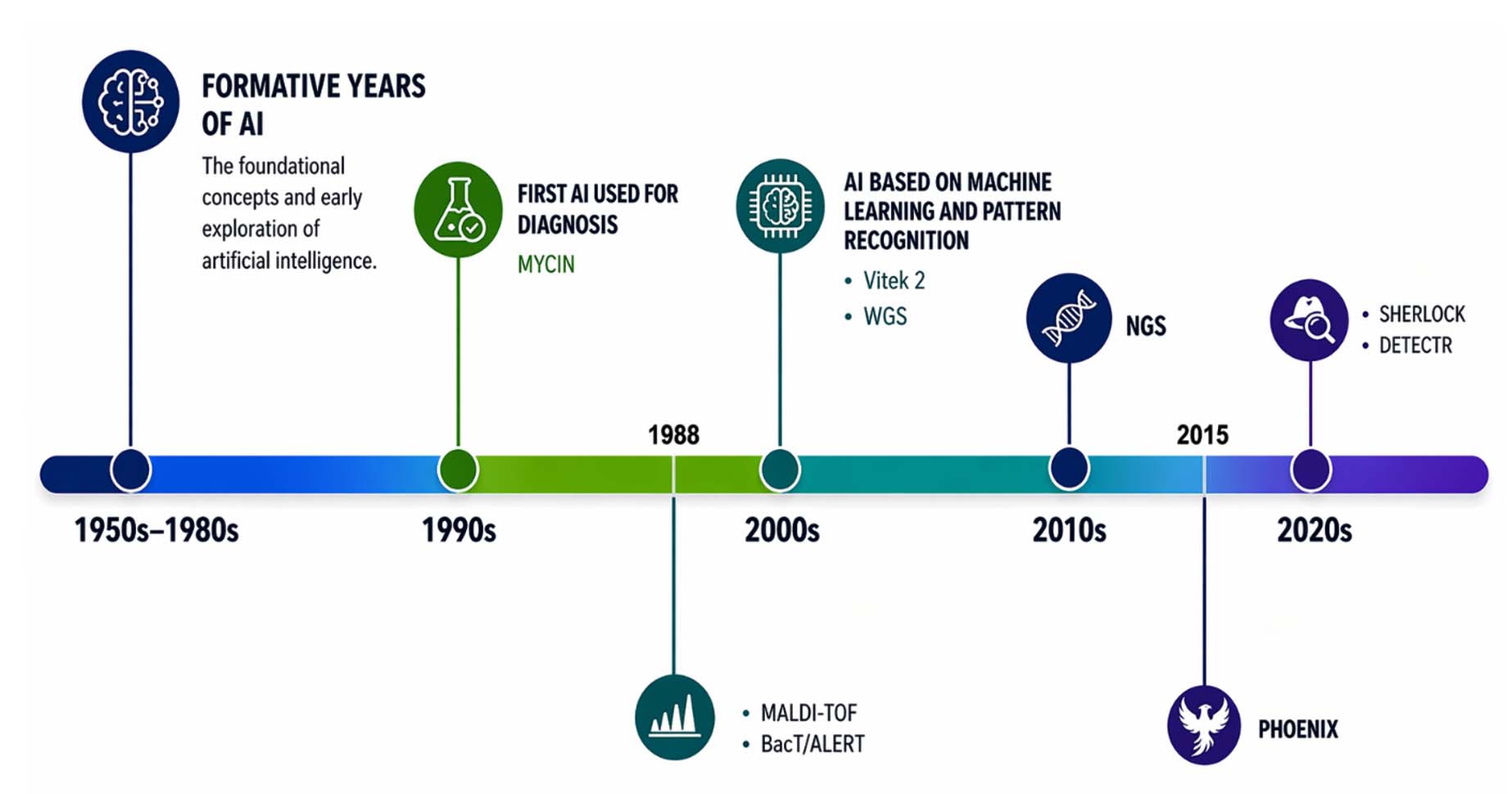
Figure 1. Overview of the evolution of artificial intelligence in medical diagnostics, highlighting key milestones and advancements (Source: Created through Miro AI)
Artificial Intelligence in Microbial Diagnostics: A Deep Dive into Models, Mechanisms, and Outcomes
The AI models discussed below represent different mathematical approaches to classification and regression problems in microbial diagnostics. While their underlying mathematics varies considerably, they share common goals: to identify patterns in complex microbial data, classify organisms accurately, and predict characteristics such as antimicrobial resistance. Understanding these models’ strengths and limitations is essential for appropriate clinical implementation.
Predicting antimicrobial resistance and analysis of bacterial growth patterns reflect some of the advantages of the artificial intelligence in microbial research and diagnostics. Therefore, it becomes imperative to comprehend how an AI algorithm functions before we can enhance these tools or fix their shortcomings. While the mathematical foundations of these models may be complex, the core principles are accessible to anyone with a keen interest in the subject. In the following sections, we will explore some of the most commonly used AI algorithms and their applications in microbial analysis.
K-Nearest Neighbours (KNN)
K-nearest neighbours (KNN) is a widely used algorithm used in various types of microbial diagnostics. The KNN algorithm classifies microbial species by comparing them with pre-existing data inputs. The K-value in KNN denotes the closest number of related specimens or “neighbours” in the dataset.19 For example, in the case of sample identification, the KNN searches for the nearest neighbours in the dataset based on various parameters. Also, in the case of the classification of a novel microbe, KNN can categorise the new microbe by comparing it with neighbours based on adjusting the K-value.20 Here the K-value signifies the number of organisms against which the organism of interest is tested on various parameters.19 The K-value becomes relevant to the accuracy of the search result as increasing or decreasing this value influences the outcome of the result, therefore, the optimal K-value ensures a suitable balance between capture patterns and noise from irrelevant results.19 There are quite a lot of applications of KNN in microbial diagnostics, aiding in and improving the accuracy of search diagnosis. One such application was when a group of researchers detected the presence of bacterial species (Escherichia and Salmonella typhimurium) in biofilms using Fluorescence Hyperspectral Imaging.21 Various ML algorithms were utilised in this study but the most prominent among them was KNN which facilitated the classification of fluorescence data. It achieved over 90% specificity in detecting and categorising biofilm bacteria, showing a higher degree of efficiency over other AI models.21 Another research conducted by Trunojoyo University provided evidence in the ability of KNN to classify accurately, which allowed them to classify bacterial species such as Vibrio cholerae, Staphylococcus aureus, and Streptococcus based on existing microbial data available on existing datasets with over 91.11% accuracy (with K = 5) and over 97.77% (with K = 9) by utilising Chebyshev method.20
Logistic Regression (LR)
The logistic regression type of ML algorithm is a deterministic and statistical method used for ‘Binary Classification’, which means it gives the output in the form of absolute states such as ‘yes’ or ‘no’, ‘infected’ or ‘not infected’ etc. Hence, this type of algorithm is known as a “Classifier Algorithm” and is primarily used in situations where the outcome is dichotomous. This algorithm analyses all the variables present in a regression-like function and coalesces the result (based on the decision boundary) into a definite category classifying it into one of the two categories present.22,23 This algorithm can be trained with data to obtain specific results such as the presence of specific pathogens or specific biomarkers in blood, urine or food.24 For example, the dataset that has been used to train the algorithm comes from various tests which may have resulted as positive or negative based on the presence of a pathogen in the sample based on the decision boundary which is nothing but a threshold value beyond which the algorithm makes the decision. Then it represents the provided data as a sigmoid curve which denotes the chance of an event occurring. When the test data is fed into the algorithm it finally terminates the outcomes in one of two binary outcomes available and that is the working of this algorithm in a concise form. Among various applications of logistic regression such as microbial classification,25 logistic regression offers various uses such; LR studies have found the link between a disbalance between gut microbiota and diseases like irritable bowel syndrome (IBS) or Crohn’s disease26; LR models can also incorporate microbial biomarker data to predict the presence of microbes well before the presence of symptoms.24 Logistic regression is a versatile tool in microbial diagnostics, providing reliable, interpretable, and fast predictions. Despite some limitations in handling complex, non-linear relationships, logistic regression remains a valuable method, especially when combined with careful feature selection and appropriate data-handling techniques.22
Naive Bayes (NB)
The naive Bayes algorithm is a robust, non-probabilistic, conditional algorithm suitable for large datasets.27,28 The term ‘Naive Bayes’ is divided into two terms; the algorithm is based on the Bayes Theorem which “The conditional probability of an event A, with respect to another event B which has occurred priorly as a quotient of probabilities of both the events A and B occurring individually”.27,28 The ‘Naive’ part of the term confers the fact that attributes used to come to the final output are considered independent of each other.27,28 For an analogy, to identify an object such as a lemon, the possible attributes can be its colour (yellow), shape (round) and nature (citrus). These features are independent of each other, meaning that they do not influence each other but yet together they help to classify the object based on these very attributes from vaguely different objects such as the sun which even though it is round and yellow, is not citrus and also differs from a lemon in terms of its size and physical and chemical composition. NB assigns each object a class based on the input and predicts the class with the highest probability as the output of the sequence.29 Due to its simplicity and effectiveness, NB possesses various applications in diagnostics.30 Recently, a study conducted has highlighted the benefits of Artificial Intelligence (AI) utilised Naive Bayes (NB) algorithms to predict hospital-acquired infections (HAIs). This approach significantly improved the ability to detect multiple infections by analyzing specific attributes, enabling accurate differentiation between infected and non-infected individuals with significant precision.30 Another study leveraged AI detection capabilities to determine certain biomarkers in the gut microbiota that are linked with Lung Adenocarcinoma (LUAD).31 In conclusion, the Naive Bayes is a powerful tool utilised in microbial diagnostics due to its simplicity, efficiency, and effectiveness in processing large genomic datasets. It also enables rapid and accurate pathogen detection, antimicrobial resistance profiling, and infection risk prediction, which can be crucial while working on real-time clinical applications. Its probabilistic approach effectively manages complexity and accounts for noise in microbiological data, making it ideal for high-throughput sequencing and microbial classification.30
Support Vector Machines (SVM)
SVMs or support vector machines are a powerful class of AI algorithms, capable of higher dimensional (or simply n-dimensional) regression and classification of clinical or non-clinical data.32 In SVM, a suitable algorithm assigns classes for different points of data on a graph and tries to find a plane of separation or a ‘hyperplane’.32,33 This hyperplane acts as a margin between classes of data points based on given parameters and hence becomes suitable as a classifier that can function linearly and non-linearly as well. It is similar in function to LR but varies vastly in its design, classification and regression aspects.33 SVM regresses data by maximising the margin between classes of data points while LR performs a regression-like function to determine the probability of an outcome by first screening it through a decision boundary which collapses the result into a binary outcome and then represents the data as a sigmoid curve for analysis.32,33 SVM has been widely used recently in the field of microbial diagnostics due to its ability to compute complex, high-dimensional datasets that are typical of microbial and genomic data.34 Studies have successfully classified microbial pathogen species based on their DNA and RNA sequences. This was accomplished through SVM, which analyzed thousands of gene expression levels within the genetic data of various pathogenic strains.34 Another research even showed the prowess of this technology when integrated with other existing techniques such as MALDI-TOF MS (Matrix-assisted laser desorption ionization-time of flight mass spectrometry). SVMs, when trained on labelled data and integrated with MALDI-TOF MS, were able to classify unknown spectral patterns in given samples, massively reducing time in microbial identification.30 Despite its limitations such as high computational cost and high sensitivity to outlier data, SVM is widely used in biological research.35
eXtreme Gradient Boost (XGBoost)
XGBoost is a robust machine-learning algorithm typically designed for supervised learning tasks such as classification, regression and ranking.36 It utilises an ensemble learning approach through which it can achieve high accuracy and efficiency, making it suitable for processing complex datasets, such as those encountered in diagnosis of microbial data.36,37 Ensemble learning involves the use of weak learner models such as decision tree (DT) model37 that operate sequentially to reduce errors from previous iterations.36,37 XGBoost utilises multiple weaker learner models to reach to the outcome and achieve the aforementioned tasks. The decision tree algorithm is widely used in AI and ML is primarily utilised for regression and classification tasks.36 As the name suggests, a decision tree forms a structure with various nodes that closely resemble the shape of a tree.38 A typical decision tree consists of the following nodes: root node, internal node and leaf node. The root node is the entry point of the data.38 Further splitting of data occurs based on the highest information gain. Data then goes to internal nodes where further decisions are made based on values specific to attributes of the data that is fed.38 The data finally ends up as leaf nodes which signifies the final classification or regression value.38 Both XGBoost and Decision Tree (independently) can process large data sets while maintaining interpretability throughout the operation.39 Therefore, XGBoost has numerous applications in microbial diagnostics.40 A notable use case is in the prediction of antimicrobial resistance pathogenic strains, specifically bacterial strains.34,37 XGBoost has successfully predicted antimicrobial resistance in bacterial strains, with studies forecasting minimum inhibitory concentrations (MIC) for Klebsiella pneumoniae isolates, indicating the identification of drug-resistant and virulent strains. In Another study XGBoost models in conjunction with SHAP (Shapley Additive exPlanations) has been used to predict water contamination by targeting the classification of faecal water indicator bacteria such as Escherichia coli in water samples.34,41 Moreover, XGBoost has also been used effectively in disease diagnosis, specifically in the diagnosis of colorectal cancer in patients.34 This study indicates that XGBoost can differentiate between individuals with colorectal cancer and those in good health by categorising microbiome samples from patients with the disease.34,42
Artificial Neural Network (ANN)
Artificial neural networks are computational models that seek to mimic the structural and functional intricacies of the human brain. In human the nervous system’s functional unit is made up of billions of neurones. Similar to this, a neural network is made up of various node types that communicate with one another and create internodal connections depending on both the threshold value that mimics reasoning and the rigorous model training.43,44 A general ANN has primarily three types of nodal layers based on their roles; the first is the input layer which can only receive data and relay it to the hidden layers. The hidden layer consists of interconnected nodes working sequentially, relaying information until it concludes with a reasonable outcome.44 Then the information is relayed to the output layers which process the reasoned knowledge done by the hidden layers and produce the outcome.44 In general, ANN is referred to as ‘Black Box’ AI because the connections within the nodes of the hidden layer and its processing cannot be monitored or tracked.45 This lack of transparency creates a lack of bias in computational reasoning which gives it the capability to correct and refine its output.45 ANN shows prospects in the field of microbial diagnostics as it is capable of information storage and retrieval. This type of AI contains a logic centre and hence, is the only algorithm capable of identifying single-species polymorphism45 Another study done on ANNs proved to be more efficient in diagnosing spectral data from mass spectrometry and Raman spectrometry data than conventional methods. Furthermore, without requiring any significant preparations, ANN trained with spectral data from Surface-Enhanced Raman Spectroscopy (SERS) and Raman spectroscopy was able to achieve high sensitivity detection of pathogens like Salmonella and E. coli from unlabelled data.46
Random Forest (RF)
Random Forest AI is also a type of ensemble AI, recognised for its capability of executing complex regression and classification tasks on supervised as well as unsupervised data.47 In order to accomplish this, RF uses several Decision Trees (DT) applied gradually to marginally different subsets or variations of the data.47,48 This is one of the main features of RF that allows it to perform better with both labelled and unlabelled data by accounting for and correcting overfitting. The algorithm was trained on this dataset, and each tree within the random forest applied specific criteria to make individual decisions. These decisions are then aggregated through a voting mechanism, with the majority choice determining the final output.47 The ensemble nature, allows this AI to approach the same data from different perspectives ensuring that it simply does not memorize the whole data but learns from it and applies the information gained to other data as well.47 Due to its versatility, RF has been used widely across various fields. In the field of microbial diagnostics, RF has proven particularly effective in detecting rare microbial species in complex samples. This capability is essential for diagnosing infections involving multiple microbes and conditions linked to the gut microbiome,48 Instead of isolating species anomalies from a large microbial dataset, the RF model can be trained to eliminate background noise (essentially, the genetic data of known microbial species). This process enhances its sensitivity to rarer microbial species, effectively performing feature selection. RF can also handle nonlinear relationships as well, it is capable of identifying a plane of classification even when there are multiple features or lines of differences involved.49 Due to its ensemble nature and the tendency of the model to work on variant data subsets allows the model to be robust and allows a higher degree of classification even with large microbial data.48 A summary and classification of different AI models based on their functionalities and practical applications is presented in Figure 2.
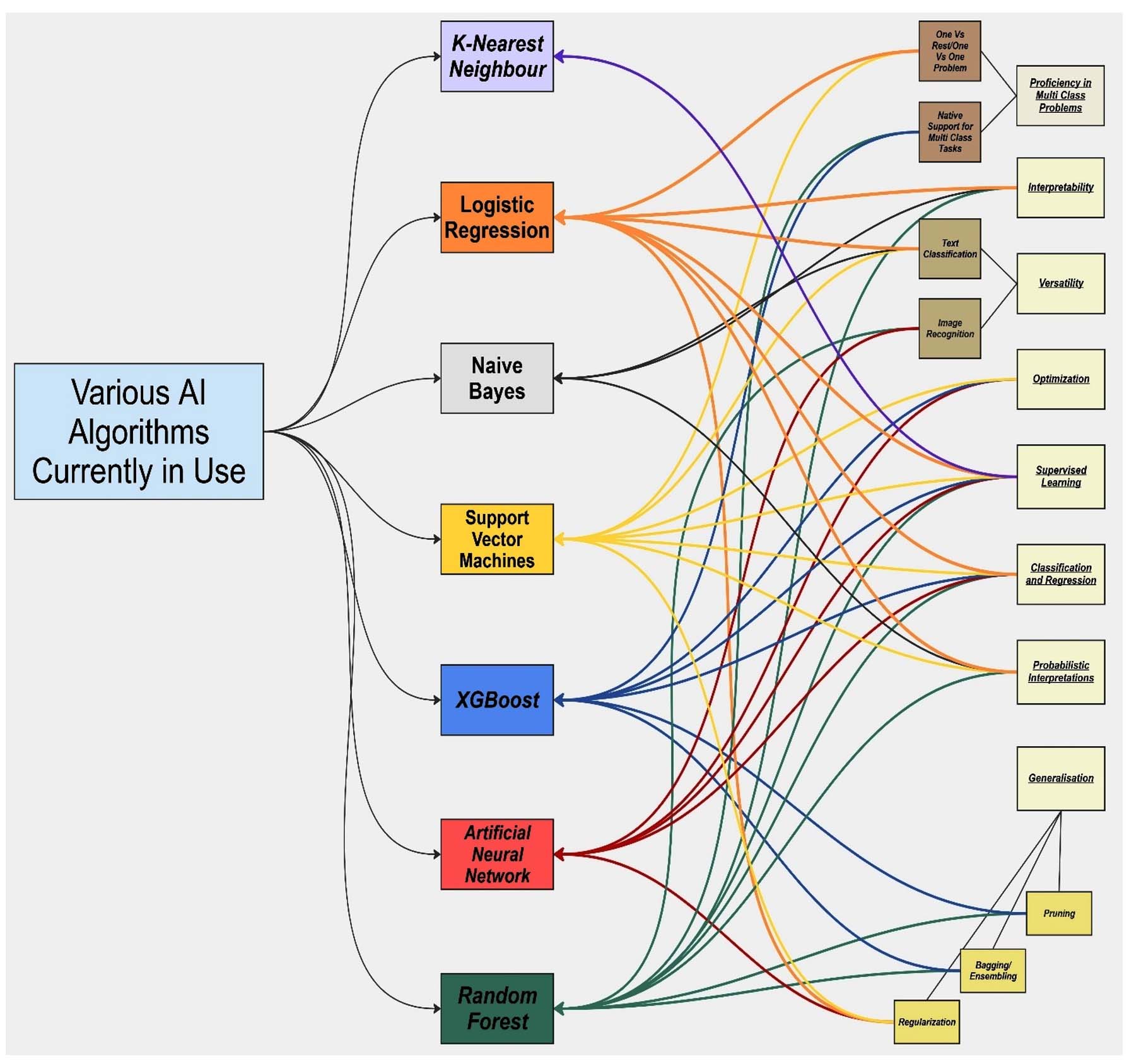
Figure 2. Summary and categorization of various AI models based on their function and utility (Source: Created through Miro AI)
Limitations of AI in diagnostics
In the previous section, we reviewed the evolution of AI, the various types of AI models, and their applications in microbiological diagnostics. The following section will examine the limitations of these earlier approaches as well as contemporary industry models and their broader implications. Understanding and addressing these gaps is essential for improving model design and ensuring adaptability to emerging diagnostic challenges.
How AI models are not specific?
Most AI models lack the specificity to distinguish between closely related bacterial species or various bacterial strains.50 Training the model in a large data set becomes a bargain between balancing excessive noise from unwanted data and maintaining optimal specificity to identify and classify the organism with high certainty. This phenomenon is known as the sensitivity-specificity trade-off.51,52 This dilemma is more pronounced when dealing with large sample data.51,52 However, there is also a catch in developing AI for specific microbial screening and diagnosis. The development of a specific AI model will lead to a loss in sensitivity as for a rarer/specific microbial strain, there will be less data on which the AI can be trained.34,53 This negates any chances of acquiring any false positive results but the opposite can be observed when dealing with rare microbial species in a large microbial data set.53,54 In clinical applications, most AI models are mainly designed to prioritize sensitivity to negate missing potential disease-causing microbes.53,54 A recent study also highlighted this limitation, reporting that although AI models have shown strong performance in pathogen identification, accurately differentiating closely related species remains challenging because of the presence of homologous sequences.55 Due to this, the alignment of unique pathogenic genomic data from reference genomes becomes a challenge due to the short size of the pathogenic genomic sequence.55 Another study utilized miRNA (MicroRNA) biosensors for the detection of pathogenic microbes.56 They also utilized AI assistance for the characterization and identification of microbial species. However, the similarity in miRNA sequences among closely related pathogenic species proved to be a challenge for AI to distinguish which led to the generation of false results.56 All this, however, can reduce specificity, making the AI model more susceptible to false positives.53 Other factors such as the dominance of common species and inadequate feature selection for classification, adversely affect the characterisation capabilities of an AI as both these factors are the consequence and the cause, respectively, of the aforementioned sensitivity-specificity trade-off.57,58 Additional factors such as data heterogenicity induce further biases which can potentially reduce the accuracy of diagnosis.59 To mitigate the chances of error, the AI algorithm must be trained with expansive, large data sets and requires better levels of association even with higher-order classification. This limitation is very critical as to why AI models are not confidently adopted on a wider scale.
Threat of reproducibility crisis
The application of AI in microbial diagnostics faces a reproducibility crisis similar to that observed in broader scientific research. Many AI models demonstrate impressive performance on their development datasets but fail to replicate these results when applied to independent clinical populations. This occurs due to several factors: (a) training datasets that don’t represent the diversity of real-world clinical samples, (b) overfitting to institution-specific laboratory practices or patient demographics, (c) lack of standardized validation protocols across studies, and (d) publication bias favouring positive results. Recent evidence shows that AI diagnostic models’ performance often drops 10%-30% when validated externally, highlighting the critical need for multi-centre validation studies before clinical deployment.
Current AI models have been able to achieve tremendous achievements in the fields of biology, medicine and other clinical sciences. These AI models show great promise and prospects for revolutionizing diagnostics across various disciplines. However, despite all the capabilities of these AI models, the adoption of AI on a wider scale has not occurred yet. This lack of adoption can be attributed to several factors which need to be addressed before any widescale implementation. The unpredictable nature of AI models such as ANNs creates a void in understanding how the AI comes to its conclusion. The Blackbox nature of the AI raises concern as there is no way of tracking how the hidden layers interpolate the information and how it is projecting the result.60 Extrapolating this information on a larger scale can become a challenge as unknown anomalies or unknown errors or biases can affect the outcome, producing erroneous results and eventually creating uncertainty around outputs.61,62 Insufficient data can also lead to models not being able to generalize microbial data across different strains, resulting in poor diagnostic accuracy.3 Furthermore, the lack of a large amount of clinical data sets is the very reason as well as the cause of AI not being implemented into widescale operations.63,64 Any regulatory body around the world will require high clinical validation to permit any large-scale use.65 This validation requires the creation of large and diverse data sets in order to train and form a robust AI model that can diagnose disease and identify causal organisms with high certainty in a manner that remains consistent to a higher degree.65-67 Specific pathogen identification algorithms that incorporate ML (machine learning) or DL (deep learning) require large data sets to accurately assess variations in the genome to identify differences in microbial species.5 Such large-scale testing at a clinical level is yet to be seen but despite we can acquire such large data sets, understanding complex polymicrobial interactions between disease-causing microbes and gaining plausible data for classifying rare microbial species will still be a challenge.
Small data set
Taking inferences from the previous section, it is sufficient to say that AI models require extensive data sets to characterise microbial species, AMR species, or a particular species of interest in polymicrobial infections.5 There are many reasons why we need large data sets, and all of them are necessary to create a finer line between what is required and what is not. The primary factor we need extensive data, as mentioned earlier, is to achieve a higher level of characterisation in multiple parameters, not just in a single parameter.68 These parameters may include differences in genes, their expression (meta transcriptomic data), surface proteins or metabolites produced.68 Another reason for necessitating large data acquisition is to classify and characterize rare microbial species.69 Training an AI model to identify rare microbial species in a polymicrobial infection is often difficult as there is simply very little data present about rare microbial species as compared to common ones.69 This skewed distribution of data creates a bias in the AI model, making it easier to identify more common species as compared to rarer ones simply because there is not enough data.7 This dilemma is highly accentuated when classifying new or even rarer species.70 Fortunately, when classifying rarer species, AI such as RF may perform with adequate accuracy as there is still some metagenomic sequencing data, 16S rRNA amplicon sequence data, or gene expression (meta transcriptomic data).70 But in the case of classifying new bacterial species, there is simply no existing data that can be referred to and therefore can become challenging to form a line of difference between species and decide on what metric to distinguish them with comfortable certainty.70 Unfortunately, due to the lack of this data, it becomes difficult to implement this diagnostic method in a clinical setting.
Reliance on supervised data and supervision and lack of improvisation
The reliance of AI models on supervised data is another one of the key limitations that still puts a question on its wide-scale implementation, especially in microbial diagnostics. Supervised learning involves training AI models on labelled datasets, where input data are paired with known outputs. In microbial diagnostics, this refers to using datasets where microbial genomic sequences are linked to specific pathogens or resistance profiles. Dependency on extensive high-quality labelled data for training an AI model is a very crucial prerequisite for high-degree regression and classification.71,72 This can become an issue with rare and novel microbial species within a vast diversity of microbes.71 Studies have shown that most AI models work better on generalised data. In the case of heterogeneous data, most AI models lack perfect generalisation capability, resulting in overfitting or skewing of results towards the posterior distributions.72 Furthermore, according to every new data set, there is a constant need to adjust the priors, R-value, sensitivity and specificity parameters to obtain suitable results.73 This also becomes a problem when dealing with novel microbial species, where there is no idea of what to expect.73 Lack of estimating absolute prediction capabilities coupled with sub-optimal parameter fitting produces erroneous results and give a false diagnosis.73 As supervised AI rely on existing data, they struggle to characterize unknown pathogens from more than just a mere estimate. There is also a clear lack of improvisation within the AI model on how to handle noise and bias, how to maintain sensitivity-specificity balance with polymicrobial interactions, and how to adapt to automatically detect rare microbial species within a large unlabelled sample of genomic data. Furthermore, high dimensionality of data, data quality and standardization, and variations in interpretations can all affect the capability of an AI model to produce quality results.5,71,74 Addressing these challenges requires collaborative efforts to develop comprehensive, high-quality datasets, implement robust data preprocessing and standardization protocols, and design AI models that are both accurate and interpretable.75 By tackling these issues, the application of AI in microbial diagnostics can be optimized, leading to improved patient outcomes and more effective public health interventions. The limitations of different AI algorithms are outlined in the Table.
Table: Summary of shortfalls of various Artificial Intelligence algorithms
Challenges |
Description |
Implication |
|---|---|---|
Lack of Specificity |
AI models often struggle to differentiate between closely related bacterial species or strains due to homologous sequences and short pathogenic genomic segments. |
This limitation can lead to misidentification, resulting in inappropriate treatment plans and potential patient harm. |
Sensitivity-Specificity Trade-off |
Balancing sensitivity and specificity is challenging; enhancing one often compromises the other, especially with rare pathogens due to limited training data. |
A high sensitivity may increase false positives, while high specificity may miss actual infections, affecting diagnostic reliability. |
Data Heterogeneity |
Variability in data sources, formats, and quality introduces biases, reducing the accuracy and generalizability of AI models. |
Inconsistent data can lead to unreliable diagnostics and hinder the model’s applicability across different clinical settings. |
Limited Clinical Data |
The scarcity of comprehensive, high-quality clinical datasets hampers the training and validation of AI models. |
Without robust datasets, AI models cannot achieve the accuracy required for clinical adoption, delaying their integration into healthcare. |
Overfitting Due to Small Datasets |
Training AI models on small datasets can lead to overfitting, where the model performs well on training data but poorly on new, unseen data. |
Overfitting results in models that lack generalizability, making them unreliable for broader clinical application. |
Reliance on Supervised Learning |
AI models often depend on labeled data for training, which is scarce for rare or novel pathogens. |
This reliance limits the model’s ability to identify emerging or less-studied pathogens, reducing its diagnostic scope. |
Black-Box Nature of AI Models |
Many AI models, especially deep learning, operate as “black boxes”, offering little insight into their decision-making processes. |
The lack of interpretability raises concerns about trust and accountability in clinical diagnostics. |
Regulatory and Validation Challenges |
AI models require extensive validation and regulatory approval before clinical deployment, which is time-consuming and complex. |
Delays in approval processes can slow down the integration of AI diagnostics into healthcare systems. |
Ethical and Privacy Concerns |
The use of patient data in AI models raises issues related to privacy, consent, and data security. |
Ethical concerns may limit data sharing, affecting the development and training of robust AI models. |
Integration with Existing Clinical Workflows |
Incorporating AI diagnostics into current clinical practices requires significant adjustments and training. |
Resistance to change and the need for new infrastructure can hinder the adoption of AI technologies. |
Ethical concerns
Apart from the aforementioned limitations of current AI, there certain risks and ethical considerations which should be understood and accounted for prior translational studies. Foremost of these issues is processing of patient data. Privacy and security of personal data and consent on the use of sensitive patient genomic and clinical information necessitates stringent safeguards to prevent breaches and misuse.76 Additionally, unknown biases caused by an unoptimized algorithm may produce false diagnoses causing serious repercussions on patient’s health and generating provident inferences based on such generated data. Furthermore, there is a major uncertainty in assessing how AI such as ANN reach to their conclusion. Such unknown decision logic may create discrepancies when subjected to a larger dataset. The black-box nature of many AI systems also compromises transparency and explainability of the mechanistic pathway taken to reach the results, making it difficult for clinicians to fully trust or validate the rationale behind AI-generated decisions.45 Finally, there is a growing need to address access and equity, ensuring that the benefits of AI-driven diagnostics are not limited to well-resourced institutions but are made accessible across diverse healthcare settings to promote fairness and inclusivity. Addressing these ethical challenges is essential for the responsible and equitable integration of AI into clinical microbiology.77
Artificial Intelligence has matured from a promising experimental approach to an increasingly integral component of microbial diagnostics, with established applications in pathogen identification, antimicrobial resistance prediction, and outbreak surveillance. Technologies such as MALDI-TOF MS integrated with machine learning, deep learning-enhanced genomic analysis, and AI-powered microscopy have demonstrated substantial clinical value. Recent advances, including open-set deep learning approaches that can identify novel pathogens (achieving 93% accuracy for target pathogens while reducing false positives by 36% in real-world air samples) and automated malaria detection systems (reaching 94.3% detection accuracy), demonstrate AI’s expanding capabilities.
In this review we have explored the evolution of AI in microbial diagnostics, from MYCIN’s rule-based systems to contemporary machine learning and deep learning architectures such as XGBoost and convolutional neural networks (CNNs). Despite remarkable progress, several challenges continue to limit broader clinical adoption.
The specificity-sensitivity trade-off remains particularly pronounced when distinguishing closely related species or rare pathogens. Many AI models suffer from limited generalizability across diverse clinical settings, populations, and microbial strains, often showing performance degradation during external validation. The dependence on extensive, high-quality labeled datasets presents additional barriers, particularly for emerging pathogens and resource-limited settings. Furthermore, the “black-box” nature of advanced deep learning models raises concerns regarding interpretability, transparency, and clinical trust.
Addressing these limitations will require coordinated efforts across multiple strategic domains. Multi-centre validation studies are essential to establish robust real-world performance benchmarks beyond development datasets. The SEPSIS-SHIELD study exemplifies this approach, demonstrating successful prospective validation across international clinical settings and supporting regulatory approval. Similarly, hybrid intelligence systems that combine AI-driven analytical power with traditional microbiological expertise offer a pragmatic pathway toward reliable and clinically acceptable diagnostic solutions. Platforms such as TCINet and Deep Colony illustrate how AI can complement rather than replace expert judgment.
Future preparedness for emerging infectious diseases will depend heavily on adaptive learning frameworks, particularly open-set and transfer learning approaches capable of identifying previously unseen pathogens without extensive retraining. The COVID-19 pandemic underscored the importance of such flexibility. Standardization of evaluation protocols through frameworks such as FUTURE-AI, TRIPOD-AI, and PRISMA-AI will further improve reproducibility, comparability, and regulatory acceptance across studies.
Unbiased implementation of AI also remains a critical priority. Current geographic imbalances in training datasets risk reinforcing healthcare discrepancies. Federated learning approaches, which enable collaborative model development while preserving data privacy, may help address both equity and ethical concerns. Concurrently, regulatory frameworks must continue evolving to accommodate continuously learning AI systems while maintaining patient safety, transparency, and accountability. International harmonization of regulatory standards could facilitate responsible global deployment.
Finally, the development of explainable AI methodologies is fundamental to building clinician confidence and promoting adoption in routine practice. Techniques such as SHAP and LIME provide interpretable insights into model decision-making, enabling clinicians to verify that AI predictions align with established microbiological and diagnostic principles.
In conclusion, AI possesses the potential to transform microbial diagnostics by improving diagnostic speed, accuracy, scalability, and clinical decision-making. However, realizing this potential will require rigorous validation, improved explainability, standardized evaluation frameworks, equitable data representation, adaptive learning capabilities, and robust regulatory oversight. By addressing these challenges, AI can evolve from a promising technological innovation into a trusted clinical standard that enhances diagnostic precision while preserving the indispensable expertise of microbiologists and healthcare professionals.
ACKNOWLEDGMENTS
The authors gratefully acknowledge the support provided by School of Biosciences and Technology, Galgotias University, in facilitating the resources and environment necessary for the preparation of this review article.
CONFLICT OF INTEREST
The authors declare that there is no conflict of interest.
AUTHORS’ CONTRIBUTION
VKY conceived and supervised the study. AAK wrote the manuscript. VKY, AAK, and IA reviewed, revised and approved the final manuscript for publication.
FUNDING
None.
DATA AVAILABILITY
All datasets generated or analyzed during this study are included in the manuscript.
ETHICS STATEMENT
This article does not contain any studies on human participants or animals performed by any of the authors.
- Sharma P, Pathak S, Pandey NK, Kumat S. A Review Paper on Artificial Intelligence. Tuijin Jishu/Journal of Propulsion Technology. 2023;44(1):163-166.
Crossref - Smith KP, Wang H, Durant TJS, et al. Applications of Artificial Intelligence in Clinical Microbiology Diagnostic Testing. Clin Microbiol Newsl. 2020;42(8):61-70.
Crossref - Zhang X, Zhang D, Zhang X, Zhang X. Artificial intelligence applications in the diagnosis and treatment of bacterial infections. Front Microbiol. 2024;15:1449844.
Crossref - Branda F, Scarpa F. Implications of Artificial Intelligence in Addressing Antimicrobial Resistance: Innovations, Global Challenges, and Healthcare’s Future. Antibiotics. 2024;13(6).
Crossref - Alsulimani A, Akhter N, Jameela F, et al. The Impact of Artificial Intelligence on Microbial Diagnosis. Microorganisms. 2024;12(6):1051.
Crossref - van Melle W. MYCIN: a knowledge-based consultation program for infectious disease diagnosis. Int J Man Mach Stud. 1978;10(3):313-322.
Crossref - Tsitou VM, Rallis D, Tsekova M, Yanev N. Microbiology in the era of artificial intelligence: transforming medical and pharmaceutical microbiology. Biotechnol Biotechnol Equip. 2024;38(1):2349587.
Crossref - Pages monteiro L, Von Allmen N, Friesen I, Huth K, Zambardi G. Performance of the VITEK®2 advanced expert systemTM for the validation of antimicrobial susceptibility testing results. Eur J Clin Microbiol Infect Dis. 2021;40(6):1333–5.
Crossref - Pozzi P, Candeo A, Paie P, Bragheri F, Bassi A. Artificial intelligence in imaging flow cytometry. Front Bioinform. 2023;3:1229052.
Crossref - Menchinelli G, Liotti FM, Fiori B, et al. In vitro Evaluation of BACT/ALERT® VIRTUO®, BACT/ALERT 3D®, and BACTECTM FX Automated Blood Culture Systems for Detection of Microbial Pathogens Using Simulated Human Blood Samples. Front Microbiol. 2019;10:00221.
Crossref - Lee YS, Choi JW, Kang T, Chung BG. Deep Learning-Assisted Droplet Digital PCR for Quantitative Detection of Human Coronavirus. Biochip J. 2023;17(1):112-119.
Crossref - de la Lastra JMP, Wardell SJT, Pal T, de la Fuente-Nunez C, Pletzer D. From Data to Decisions: Leveraging Artificial Intelligence and Machine Learning in Combating Antimicrobial Resistance – a Comprehensive Review. J Med Syst. 2024;48(1):71.
Crossref - Singhal N, Kumar M, Kanaujia PK, Virdi JS. MALDI-TOF mass spectrometry: an emerging technology for microbial identification and diagnosis. Front Microbiol. 2015;6:00791.
Crossref - Torres-Sangiao E, Leal Rodriguez C, Garcia-Riestra C. Application and Perspectives of MALDI–TOF Mass Spectrometry in Clinical Microbiology Laboratories. Microorganisms. 2021;9(7):1539.
Crossref - Qin D. Next-generation sequencing and its clinical application. Cancer Biol Med. 2019;16(1):4-10.
Crossref - Satam H, Joshi K, Mangrolia U, et al. Next-Generation Sequencing Technology: Current Trends and Advancements. Biology. 2023;12(7):997.
Crossref - Zahra A, Shahid A, Shamim A, Khan SH, Arshad MI. The SHERLOCK Platform: An Insight into Advances in Viral Disease Diagnosis. Mol Biotechnol. 2023;65(5):699-714.
Crossref - Xu J, Bai X, Zhang X, et al. Development and application of DETECTR-based rapid detection for pathogenic Bacillus anthracis. Anal Chim Acta. 2023;1247:340891.
Crossref - Venkateswarlu B, Gangula R. Exploring the Power and Practical Applications of K-Nearest Neighbours (KNN) in Machine Learning. Journal of Computer Allied Intelligence. 2024;2(1):8-15.
Crossref - Rahmawati D, Puspa PIM, Ulum M, Joni K. Identification and Classification of Pathogenic Bacteria Using the K-Nearest Neighbor Method. Journal of Electrical and Electronic Engineering-UMSIDA. 2021;5(1):60-70.
Crossref - Lee A, Park S, Yoo J, et al. Detecting Bacterial Biofilms Using Fluorescence Hyperspectral Imaging and Various Discriminant Analyses. Sensors. 2021;21(6):2213.
Crossref - Sperandei S. Understanding logistic regression analysis. Biochem Med (Zagreb). 2014;24:12-18.
Crossref - Hajmeer M, Basheer I. Comparison of logistic regression and neural network-based classifiers for bacterial growth. Food Microbiol. 2003;20(1):43-55.
Crossref - Satoto BD, Utoyo I, Rulaningtyas R. Colour segmentation of Gram-Negative bacteria using graph Quadratic Form and Random Walker. J Phys Conf Ser. 2020;1538(1):012005.
Crossref - Wahid MF, Ahmed T, Habib MA. Classification of microscopic images of bacteria using deep convolutional neural network. In: ICECE 2018 – 10th International Conference on Electrical and Computer Engineering. Institute of Electrical and Electronics Engineers Inc. 2018:217-220.
Crossref - Balbin JR, Sese JT, Babaan CVR, Poblete DMM, Panganiban RP, Poblete JG. Detection and classification of bacteria in common street foods using electronic nose and support vector machine. In: 2017 7th IEEE International Conference on Control System, Computing and Engineering (ICCSCE). 2017:247-252.
Crossref - Peretz O, Koren M, Koren O. Naive Bayes classifier – An ensemble procedure for recall and precision enrichment. Eng Appl Artif Intell. 2024;136(part B):108972.
Crossref - Wickramasinghe I, Kalutarage H. Naive Bayes: applications, variations and vulnerabilities: a review of literature with code snippets for implementation. Soft comput. 2021;25(3):2277-2293.
Crossref - Sammut C, Webb GI, eds. Encyclopedia of Machine Learning and Data Mining. Boston, MA: Springer US; 2017.
Crossref - Baddal B, Taner F, Uzun Ozsahin D. Harnessing of Artificial Intelligence for the Diagnosis and Prevention of Hospital-Acquired Infections: A Systematic Review. Diagnostics. Diagnostics. 2024;14(5):484.
Crossref - Liu Q, Zhang W, Pei Y, et al. Gut mycobiome as a potential non-invasive tool in early detection of lung adenocarcinoma: a cross-sectional study. BMC Med. 2023;21(1).
Crossref - Evgeniou T, Pontil M. Support vector machines: Theory and applications. In: Paliouras G, Karkaletsis V, Spyropoulos CD, eds. Machine Learning and Its Applications. ACAI 1999. Lecture Notes in Computer Science. Springer, Berlin, Heidelberg. 2001:249-257.
Crossref - Brereton RG, Lloyd GR. Support Vector Machines for classification and regression. Analyst. 2010;2:230-267.
Crossref - Zhang X, Zhang D, Zhang X, Zhang X. Artificial intelligence applications in the diagnosis and treatment of bacterial infections. Front Microbiol. 2024;15:1449844.
Crossref - Sabzekar M, Sadoghi Yazdi H, Naghibzadeh M. Relaxed constraints support vector machines for noisy data. Neural Comput & Applic. 2011;20(5):671-685.
Crossref - Chen T, Guestrin C. XGBoost: A scalable tree boosting system. In: Proceedings of the ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. Association for Computing Machinery. 2016:785-794.
Crossref - Gidiglo PD, Ngnamsie Njimbouom S, Aly Abdelkader G, Mosalla S, Kim JD. Multi-Label Classification for Predicting Antimicrobial Resistance on E. coli. Appl Sci. 2024;14(18):8225.
Crossref - Costa VG, Pedreira CE. Recent advances in decision trees: an updated survey. Artif Intell Rev. 2023;56(5):4765-800.
Crossref - Abedinia A, Seydi V. Building semi-supervised decision trees with semi-cart algorithm. Int J Mach Learn & Cyber. 2024;15(10):4493–510.
Crossref - Xie H, Dong C, Li Y, et al. XGBoost-based urinary microbial signatures enable non-invasive diagnosis and prognosis for urothelial carcinoma. BMC Microbiol. 2025;25(1):732.
Crossref - Choudhary R, Kumar A, Priyadharsini C, Naik MM, Choudhury M, Khan NA. Predicting water quality index using stacked ensemble regression and SHAP based explainable artificial intelligence. Sci Rep. 2025;15(1):31139.
Crossref - Novielli P, Romano D, Magarelli M, et al. Explainable artificial intelligence for microbiome data analysis in colorectal cancer biomarker identification. Front Microbiol. 2024;15:1348974.
Crossref - de Garis H, Shuo C, Goertzel B, Ruiting L. A world survey of artificial brain projects, Part I: Large-scale brain simulations. Neurocomputing. 2010;74(1-3):3-29.
Crossref - Prieto A, Prieto B, Ortigosa EM, et al. Neural networks: An overview of early research, current frameworks and new challenges. Neurocomputing. 2016;214:242-268.
Crossref - Qamar T, Bawany NZ. Understanding the black-box: towards interpretable and reliable deep learning models. PeerJ Comput Sci. 2023;9:e1629.
Crossref - Kassem A, Abbas L, Coutinho O, et al. Applications of Fourier Transform-Infrared spectroscopy in microbial cell biology and environmental microbiology: advances, challenges, and future perspectives. Front Microbiol. 2023;14:1304081.
Crossref - Boulesteix A, Janitza S, Kruppa J, König IR. Overview of random forest methodology and practical guidance with emphasis on computational biology and bioinformatics. Wiley Interdiscip Rev Data Min Knowl Discov . 2012;2(6):493-507.
Crossref - Knights D, Parfrey LW, Zaneveld J, Lozupone C, Knight R. Human-Associated Microbial Signatures: Examining their predictive value. Cell Host & Microbe. 2011;10(4):292-296.
Crossref - Chen H, Jiao J, Wei M, et al. Metagenomic analysis of the interaction between the gut microbiota and colorectal cancer: a paired-sample study based on the GMrepo database. Gut Pathog. 2022;14(1):48.
Crossref - Nalbantoglu OU, Way SF, Hinrichs SH, Sayood K. RAIphy: Phylogenetic classification of metagenomics samples using iterative refinement of relative abundance index profiles. BMC Bioinformatics. 2011;12(1):41.
Crossref - Nahm FS. Receiver operating characteristic curve: overview and practical use for clinicians. Korean J Anesthesiol. 2022;75(1):25-36.
Crossref - Altman DG, Bland JM. Statistics Notes: Diagnostic tests. 1: Sensitivity and specificity. BMJ. 1994;308(6943):1552.
Crossref - Visibelli A, Roncaglia B, Spiga O, Santucci A. The Impact of Artificial Intelligence in the Odyssey of Rare Diseases. Biomedicines. 2023;11(3):887.
Crossref - Gaston JM, Alm EJ, Zhang AN. Fast and accurate variant identification tool for sequencing-based studies. BMC Biol. 2024;22(1):90.
Crossref - Gardy JL, Loman NJ. Towards a genomics-informed, real-time, global pathogen surveillance system. Nat Rev Genet. 2018;19(1):9-20.
Crossref - Ouyang T, Liu Z, Han Z, Ge Q. MicroRNA Detection Specificity: Recent Advances and Future Perspective. Anal Chem. 2019;91(5):3179-3186.
Crossref - Jiménez-Valverde A. Threshold-dependence as a desirable attribute for discrimination assessment: implications for the evaluation of species distribution models. Biodivers Conserv. 2014;23(2):369-385.
Crossref - Chen RC, Dewi C, Huang SW, Caraka RE. Selecting critical features for data classification based on machine learning methods. J Big Data. 2020;7(52):26.
Crossref - White SJ, Phua QS, Lu L, et al. Heterogeneity in Systematic Reviews of Medical Imaging Diagnostic Test Accuracy Studies. JAMA Netw Open. 2024;7(2):E240649.
Crossref - Hassija V, Chamola V, Mahapatra A, et al. Interpreting Black-Box Models: A Review on Explainable Artificial Intelligence. Cogn Comput. 2024;16(3):45-74.
Crossref - Yousefzadeh R, Cao X. To what extent should we trust AI models when they extrapolate? arXiv. 2022.
Crossref - Graf E, Soliman A, Marouf M, Parwani AV, Pancholi P. Potential roles for artificial intelligence in clinical microbiology from improved diagnostic accuracy to solving the staffing crisis. Am J Clin Pathol. 2024;163(2):162-168.
Crossref - Kelly CJ, Karthikesalingam A, Suleyman M, Corrado G, King D. Key challenges for delivering clinical impact with artificial intelligence. BMC Med. 2019;17(1):195.
Crossref - khan B, Fatima H, Qureshi A, et al. Drawbacks of Artificial Intelligence and Their Potential Solutions in the Healthcare Sector. Biomed Mater Devices. 2023;1(2):731-738.
Crossref - Theodosiou AA, Read RC. Artificial intelligence, machine learning and deep learning: Potential resources for the infection clinician. J Infect. 2023;87(4):287-294.
Crossref - Tsopra R, Fernandez X, Luchinat C, et al. A framework for validating AI in precision medicine: considerations from the European ITFoC consortium. BMC Med Inform Decis Mak. 2021;21(1):274.
Crossref - Higgins DC, Johner C. Validation of Artificial Intelligence Containing Products Across the Regulated Healthcare Industries. Ther Innov Regul Sci. 2023;57(4):797-809.
Crossref - Kumar B, Lorusso E, Fosso B, Pesole G. A comprehensive overview of microbiome data in the light of machine learning applications: categorization, accessibility, and future directions. Front Microbiol. 2024;15:1343572.
Crossref - Harris ZN, Dhungel E, Mosior M, Ahn TH. Massive metagenomic data analysis using abundance-based machine learning. Biol Direct. 2019;14(1):12.
Crossref - Suster CJE, Pham D, Kok J, Sintchenko V. Emerging applications of artificial intelligence in pathogen genomics. Front Bacteriol. 2024;3:1326958.
Crossref - Tran NK, Albahra S, May L, et al. Evolving Applications of Artificial Intelligence and Machine Learning in Infectious Diseases Testing. Clin Chem. 2022;68(1):125–33.
Crossref - Goodswen SJ, Barratt JLN, Kennedy PJ, Kaufer A, Calarco L, Ellis JT. Machine learning and applications in microbiology. FEMS Microbiol Rev. 2021;45(5):fuab015.
Crossref - Sarantopoulos A, Kourmpani CM, Yokarasa AL, et al. Artificial Intelligence in Infectious Disease Clinical Practice: An Overview of Gaps, Opportunities, and Limitations. Trop Med Infect Dis. 2024;9(10):228.
Crossref - Mathieu A, Leclercq M, Sanabria M, Perin O, Droit A. Machine Learning and Deep Learning Applications in Metagenomic Taxonomy and Functional Annotation. Front Microbiol. 2022;13:811495.
Crossref - Gao F, Huang K, Xing Y. Artificial Intelligence in Omics. Genomics Proteomics Bioinformatics. 2022;20(5):811-813.
Crossref - Tilala MH, Chenchala PK, Choppadandi A, et al. Ethical Considerations in the Use of Artificial Intelligence and Machine Learning in Health Care: A Comprehensive Review. Cureus. 2024;6(6):e62443.
Crossref - Celi LA, Cellini J, Charpignon ML, et al. Sources of bias in artificial intelligence that perpetuate healthcare disparities—A global review. PLOS Digital Health. 2022;1(3):000022.
Crossref
© The Author(s) 2026. Open Access. This article is distributed under the terms of the Creative Commons Attribution 4.0 International License which permits unrestricted use, sharing, distribution, and reproduction in any medium, provided you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made.